
프로그램이 실행된다는 것은 CPU 버스트(Burst)1와 I/O 버스트(Burst)가 번갈아 반복되며 실행된다는 것이다. 프로그램이 실행될 때는 이와 같이 여러 종류의 Job(=프로세스)이 섞이기 때문에 CPU 스케줄링이 필요하다.
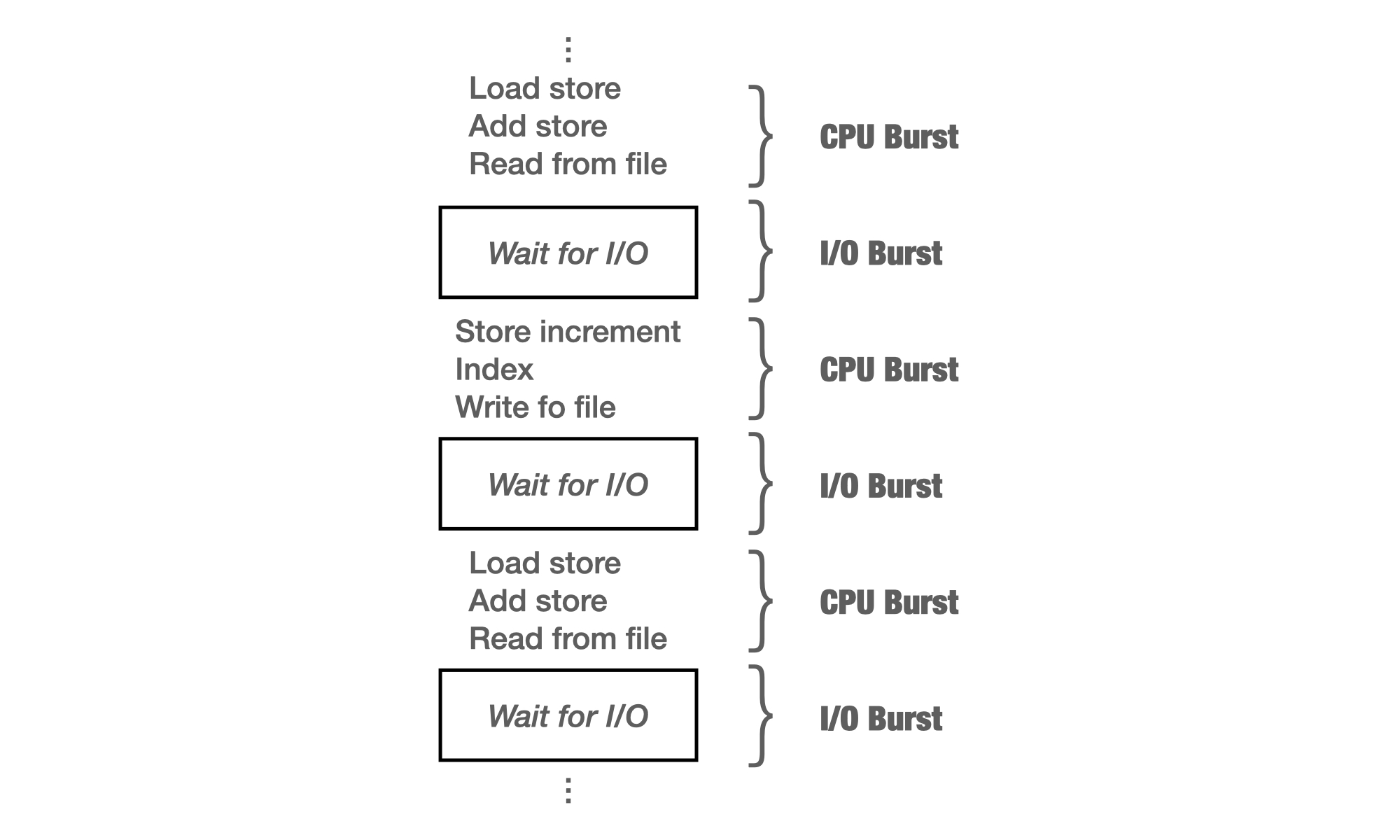
프로그램 실행 시 CPU 버스트와 I/O 버스트가 반복되며 실행된다.
CPU 스케줄링이란(CPU Scheduling)
OS는 여러 종류의 Job이 혼재된 상황에서 시스템 자원(Resource)을 골고루 효율적으로 활용하고 유휴 대기 시간을 최소화할 수 있도록 관리하는데 이것을 스케줄링(Scheduling)이라고 한다. 즉, 레디 큐(Ready queue)에 있는 프로세스 중에 어떤 프로세스에게 CPU를 줄 것인지 결정하는 것이다.
스케줄링의 세계에서는 공정성보다 효율성이 우선한다.
스케줄링은 타이머(Timer)와 같이 컴퓨터 안에 스케줄링을 담당하는 스케줄러 H/W나 별도의 S/W가 구현하지 않으며 운영체제 안의 코드로써 구현한다.
CPU 스케줄링이 필요한 상황
상식선에서 지식을 연계시키면 쉽게 알 수 있는데 스케줄링은 CPU를 빼앗고 넘기는 행위이므로 인터럽트(Interrupt), 시스템 콜(System call) 및 프로그램 종료(Terminete) 상황에서 필요하다.
디스패처(Dispatcher)
스케줄링으로 어떤 프로세스에게 CPU를 줄 것인지 결정했으면 넘겨주는 과정이 필요하다. 이러한 역할을 하는 커널 코드(Kernel code)를 디스패처라 한다.
프로세스 컨텍스트(Context)를 저장하고 새 컨텍스트를 펼치고 CPU를 넘겨준다.
프로세스 특성 분류
CPU 버스트와 I/O 버스트 중 어떤 작업 위주의 프로세스인지에 따라 특성을 분류한다.
I/O Bound Process (Many short CPU burst)
CPU를 잡고 계산하는 시간보다 I/O에 많은 시간이 필요한 Job(=프로세스)이다. 주로 사람이 조작하는 프로그램이 즉, 인터랙티브한 작업에서 이런 형태가 자주 보인다.
CPU Bound Process (Few very long CPU burst)
I/O Bound Process와 달리 CPU를 통한 계산 위주의 Job이다. 주로 과학계산 프로그램, 행렬계산, 유전자 분석, 코인채굴 등 작업에서 이런 형태가 나타나며 CPU Burst 시간이 길다.
CPU 스케줄링의 분류
모든 스케줄링은 선점형(Preemptive)과 비선점형(Non-preemptive)으로 분류할 수 있다.
선점형(Preemptive)
타이머를 두고 프로세스에게 CPU 사용시간을 할당한 뒤 할당 시간이 끝나면 CPU를 강제로 빼았는 방식으로 현대적인 OS는 Preemptive 방식을 사용한다.
비선점형(Non-Preemptive)
일단 CPU를 줬으면 CPU를 다 쓰고 자진반납할 때까지 보장해주는 방식이다.
성능 척도 (Scheduling Criteria, Performance index/measure)
어떤 스케줄러가 더 나은지, 효율이 좋은지 비교하려면 기준이 필요한데 이 기준을 Scheduling Criteria(이하 성능 척도)라고 한다. 성능 척도는 시스템 입장에서의 성능 척도와 프로그램 입장에서의 성능 척도로 구분할 수 있다.
시스템 입장에서의 성능 척도
CPU Utilization (CPU 이용률)
전체 시간 중 CPU가 놀지않고 일한 비율을 말한다. 회사에서 몸값이 비싼 인원에게 쉬지 않고 일을 주고 싶어하는 것과 같이 CPU는 비싼 자원이므로 가능한 놀리지 않고 일을 시켜야 효율이 좋다고 할 수 있다.
Throughput (처리량)
주어진 시간동안 몇 개의 태스크를 처리했는지를 말한다.
프로그램(프로세스) 입장에서의 성능 척도
Turnaround time (소요시간, 반환시간)
프로세스가 CPU를 쓰러와서 다 쓰고 나갈 떄까지 걸린 총 시간을 말한다. 여기에는 대기 시간(Waiting time)이 포함된다.
Waiting time (대기 시간)
프로세스가 레디 큐(Ready Queue)에 들어와서 기다린 시간을 말한다. Preemptive 방식에서 프로세스는 자신에게 할당된 시간이 끝나면 다시 큐의 맨 뒤에 줄서서 기다려야 하며 프로세스가 끝날 때 까지 이 사이클을 반복하는데 Waiting time은 이 모든 대기 시간을 더한 값이다.
즉, CPU를 주었다가 빼앗았다가 반복할 때 기다린 총 시간이다.
⑤ Response time (응답 시간)
레디 큐에 들어와서 최초로 CPU를 얻기까지 걸린 시간이다. 사용자 응답과 관련한 중요한 지표이다. 참고로 앞선 모든 지표들은 프로그램 입장에서 몇 개를 처리했고 얼마나 기다렸는지에 대한 것이 아니라 CPU 입장에서 레디 큐에 얼마나 많이 들어왔고 얼마나 기다리게 했고 얼마나 처리했는지에 대한 개념이다.
Algorithm Evaluation
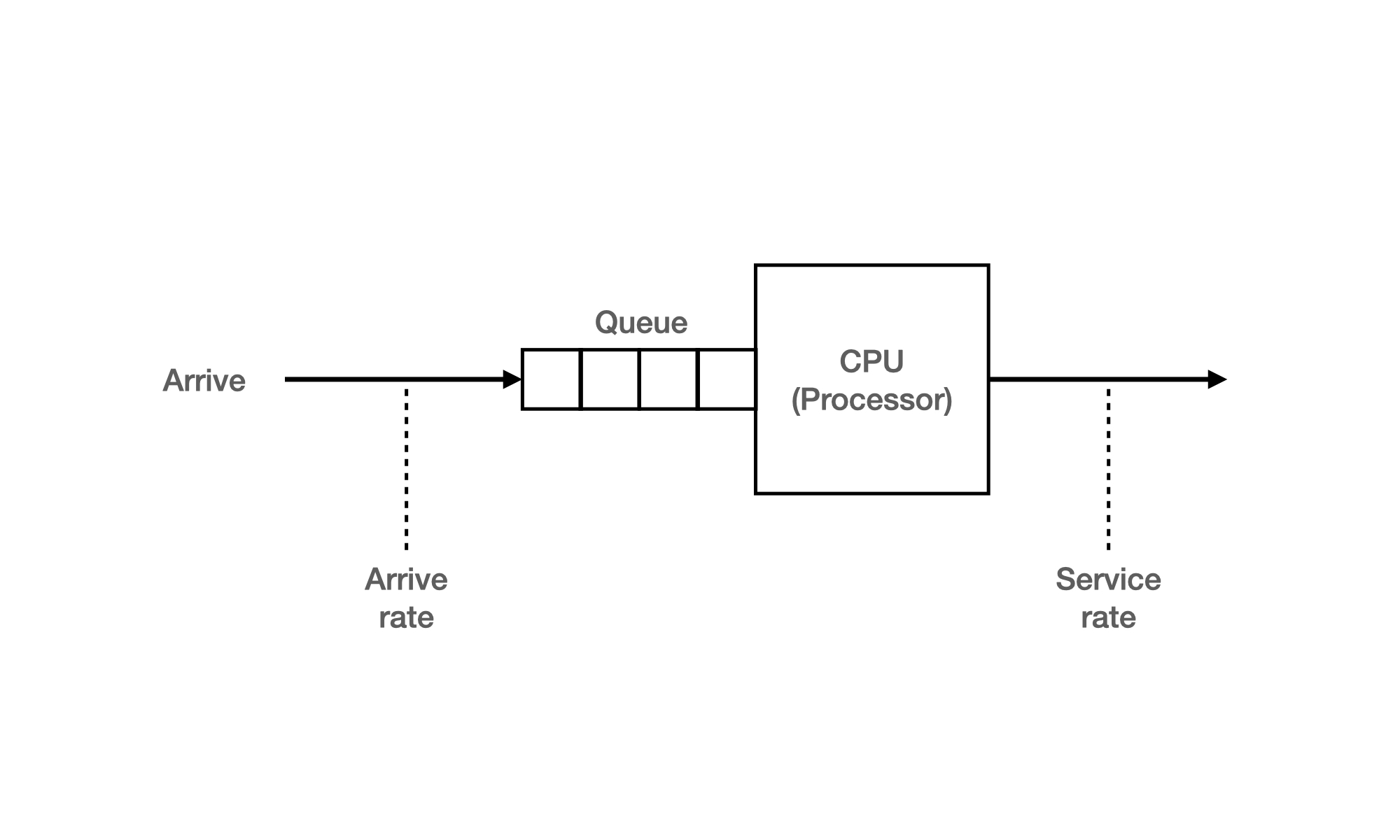
Queueing Models
이론가들이 하는 이론적인 접근 방법이라고 한다. 복잡한 컴퓨터 시스템에서는 작은 외란이 순간적으로 많이 일어나기 때문에 이론적인 값이 실제와 같을 수 없기에 이론적인 방법이라고 하는듯 하다.
Service rate와 Arrive rate와 같은 정보가 확률 분포로 주어질 때 복잡한 수식으로 계산하여 CPU Throughput이 얼마 였는지 도착한 Job이 얼마나 기다렸는지 알아내는 방법이다.
Implementation & Measurement
실제 시스템에 CPU 스케줄링 알고리즘을 구현하여 정말 돌려보고 Work load 성능을 측정 및 비교하는 방법이다. 정확한 값이겠으나 커널 코드의 스케줄링 알고리즘을 직접 수정하는 것은 투입되는 시간과 노력이 상당하다.
Simulation
Queueing models과 구현을 절충한 방법이다. 모늬 프로그램으로 작성 후 Trace(시뮬레이션 프로그램에 들어갈 Input data)를 입력하여 결과를 비교한다.
Reference
반효경, “반효경 [운영체제] 10. CPU Scheduling 1” KOCW. 2014년 3월 28일. video, “http://www.kocw.net/home/cview.do?lid=5488703b25305c37
-
짧은 시간동안 최대한 노력을 하는 것을 의미한다. ↩︎